Technical Overview
This page provides an overview of the technical solution used to build and present the I.Sicily digital corpus. The project was designed with sustainability, modularity, and openness as guiding principles.
Technologies and Processes
Data Standards
The core dataset for the project relies on the EpiDoc TEI-XML standard. This is used to encode all information about the inscriptions and the inscribed objects, as well as the actual text itself.
Data is standardised and made potentially interoperable by the use of recognised vocabularies:
- Pleiades gazetteer of ancient places
- EAGLE epigraphic vocabularies
- FAIR Epigraphy vocabularies
- BGS Rock Classification Scheme for petrographic data
Development
The project solution is built using a monorepo structure with two main components:
- An ETL (Extract, Transform, Load) process for handling and enriching XML files
- A static website built with SvelteKit configured as a Static Site Generator (SSG)
The site generates plain HTML, CSS, and JavaScript files that can be served by any standard web server (like Nginx or Apache). This means it does not require a Node.js or any other application server to be running.
Key frontend dependencies include:
- bits-ui for User Interface (UI) components
- itemsjs for faceted search
- mdsvex for markdown content
- unovis for data visualisations
- OpenSeadragon for IIIF image viewing
- MapLibre GL for interactive maps
Data Workflows and Models
The project workflow processes EpiDoc TEI XML files, enriches the original input corpus, and presents it on a static website. Individual editions are published as HTML pages but can also be searched and filtered, as well as being freely available for download.
High resolution images, where available, are presented via a IIIF server.
Annotation Layers
The corpus integrates multiple annotation layers, each feeding metadata into the inscription pages, faceted search, and other dynamic pages:
Linguistic Annotation
Linguistic annotation has been undertaken on a Greek and Latin subset of the corpus, alongside tokenisation and lemmatisation of the complete corpus.
Palaeographic Annotation
Palaeographic annotation is conducted through a dedicated digital palaeographic environment with its own web application and interface (Annotator) also served and documented via a dedicated Github repository. The environment offers a set of connected interfaces with dual use depending on the type of users. They act as an integrated environment for the researcher to curate and verify their definitions and annotations persisted over github json files. The same interfaces also works as a public and read-only view over that research dataset for any visitor. The environment lets the researcher define the palaeographic structure of allographs and then create thousands of Web Annotations (Web Annotation Data Model) that bind graphs as they appear on inscription images (using IIIF Image API region format) with their occurrences in the EpiDoc edition (fetched from a Distributed Text Services (DTS) collection) and the formal description of their structure. A faceted search interface allows any user to filter graph annotations by their structural patterns and the researcher to define a high-level typology of allographs. The list of letter types identified for each annotated inscription can be exported for inclusion into the ISicily TEI corpus file and so visible on the corpus website with links back to the palaeography environment. These types are also searchable from the ‘Lettering’ filter in the list of facet options on the Corpus website, thus integrating them with the rest of the exploration possibilities within the entire corpus, even though only a selection of inscriptions underwent palaeographic analysis.
For additional technical details, please the documentation in the github repository.
Petrographic Annotation
Petrographic analysis has been undertaken on hundreds of items across the corpus. The dataset includes raw and processed data from (geo)chemical and minero-petrographic analyses on epigraphic supports, supporting the identification of rock types and their provenance. Geology-specific vocabularies (The BGS Rock Classification Scheme) are used as reference to update the XML files with material and material provenance data. Materials description has been augmented via a dedicated RSE-supported workflow which aggregates the multi-analytical data collected by the project’s material scientist and supports (pre)processing and analysis of different data by streamlining repetitive tasks and simplifying data interpretation, eventually leading to the identification of the rocks where the texts (in Latin, Greek and other languages) are inscribed, and therefore their provenance. This research workflow is summarised in technical documentation (see diagram below), research dissemination (e.g. Coccato et al., 2025a; Coccato et al., 2025b; Ciula et. al., 2025; Ciula, 2025) and the actual code used to implement the petrographic research environment.
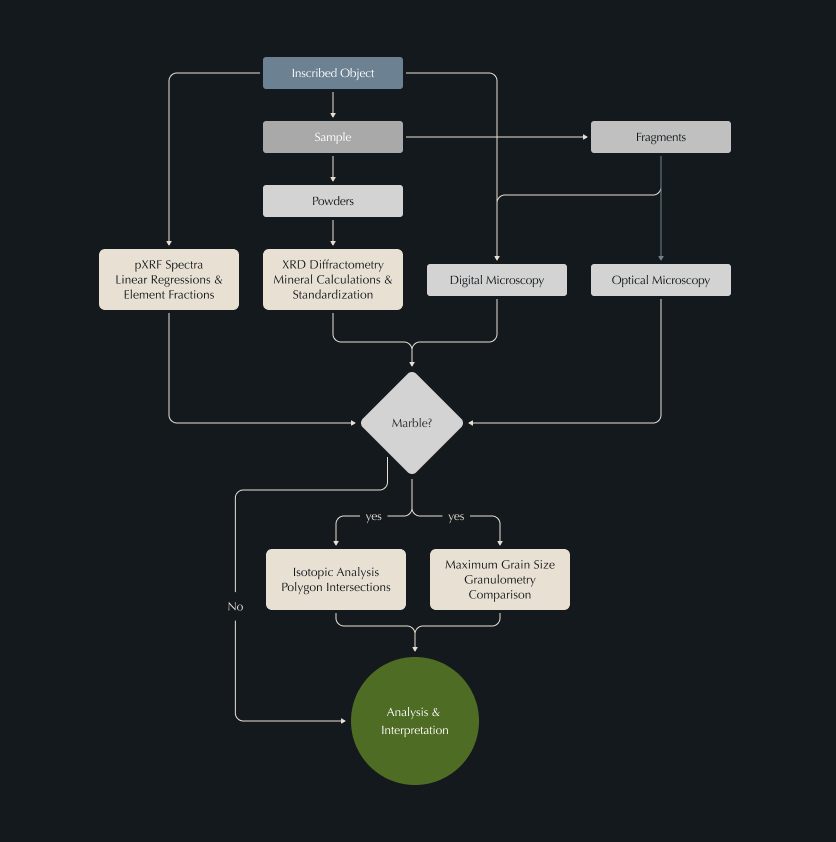
Figure 1: Petrographic analysis workflow, from sample preparation through multi-analytical characterisation to rock identification and provenance determination.
Workflows
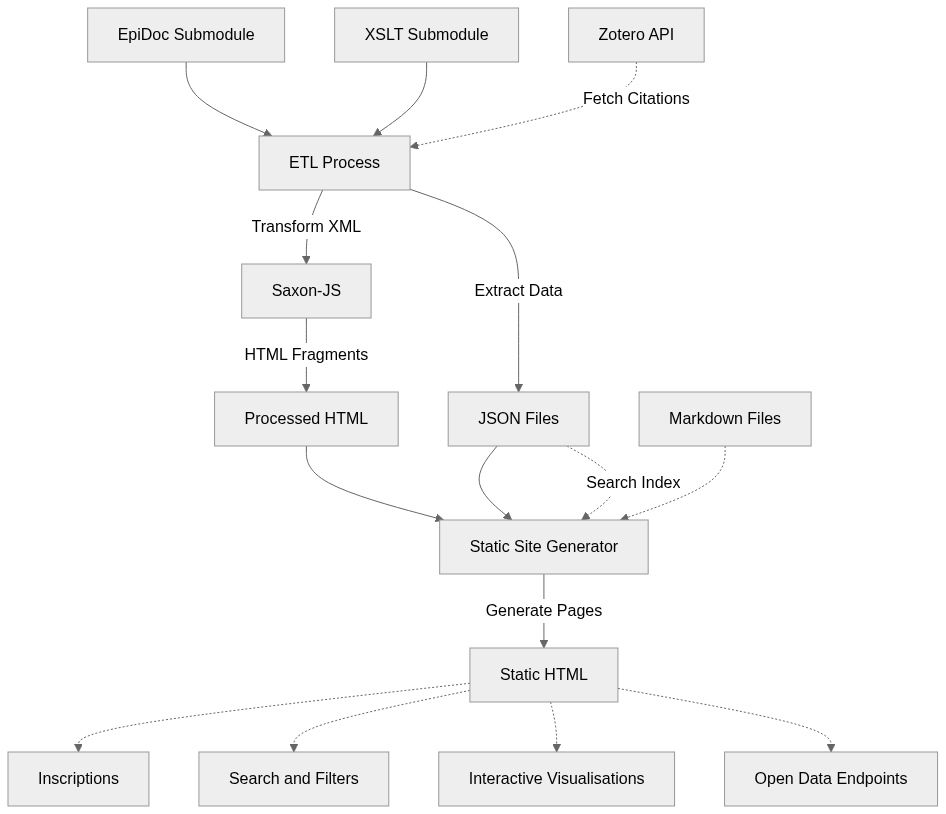
Figure 2: Corpus Building workflow, from EpiDoc source files through ETL processing and static site generation to the published website outputs.
Architecture
The project uses a monorepo structure with the following components:
| Directory | Description |
|---|---|
packages/etl/ | ETL package for processing XML |
frontend/ | Static site generator web application |
data/raw/ | Git submodule for the EpiDoc files |
data/processed/ | Output data generated by the ETL process |
xslt/epidoc/ | Git submodule for XSLT stylesheets |
Deployment
The site is available both as a staging instance for testing, and a public production site served via GitHub Pages.
The set of granular standard-compliant data files (DTS, EpiDoc, Web Annotations, etc.) versioned on and served from public code repositories is independent from the software. This portability and sustainability requirement was a consideration in all design and development work.
Design Process
The design of the site was informed by initial discussions around the information architecture and review of static mock-ups.

Figure 3: Early information architecture to map out the user experience and wireframing iterations exploring multiple feature views.
This diagram outlines the restructuring of the platform into a flatter, more accessible hierarchy compared to the previous instance of I.Sicily (see acknowledgements below). The goal was to streamline key user flows (search → results → inscription), and balance quick access for new users with advanced functionality for researchers.
The iterations below exemplified in the figures focus on structuring the core interaction model - combining search, filters, and result views (list, table, map) into a cohesive and flexible interface. The aim was to minimise cognitive load while supporting both exploratory browsing and precise academic queries.

Figure 4: Colour system exploration, balancing visual identity, readability, and accessibility.
Multiple colour palette directions were designed and tested to reflect the historical context while ensuring strong contrast and accessibility requirements. Iterations focused on readability, hierarchy, and creating a consistent visual language that works across complex data interfaces.

Figure 5: Inscription detail page design and iterations, integrating and optimising images, metadata, and academic content.
The inscription detail page was designed to handle complex, layered information: combining imagery, transcription, translation, and metadata.
In the early version, the page followed a single-column layout, with metadata positioned below the inscription image. To improve usability (particularly for comparison and reference while reading), this was redesigned into a side-by-side layout, with a fixed image and scrollable metadata panel.
Further iterations explored how to present this content clearly while maintaining academic depth and supporting different reading behaviours.

Figure 6: Landing page and search experience iterations, focusing on functionality, clarity and entry points into the dataset.
The homepage was designed to immediately guide users into the dataset through a prominent search and filtering system.
Iterations focused on hierarchy and call-to-action clarity, establishing search as the primary entry point. The design balances accessibility for first-time users with the depth and flexibility required for more advanced academic research.

Figure 7: Remote usability testing workshops.
Usability workshops with a group of representative prospective users identified bugs as well as user interface and user experience refinements which have been prioritised collaboratively and integrated into the current interface.
These were run with a mix of users to observe how they interact with search, filters, navigation, and inscription pages. Feedback was captured in real time, highlighting pain points, confusion areas, and differences between expert and non-expert users. Insights from testing informed refinements to interaction patterns, layout, and clarity. The data visualisation section builds on patterns from previous KDL projects, combining established structures with tailored UX/UI decisions for this project.
Community Value
By integrating different layers of annotations in the same publication, the site converges benefits from multiple communities:
- Researchers: Multidisciplinary researchers involved in the project are empowered to conduct data quality and analysis on the integrated corpus
- Museums: Repositories where the actual inscription objects are held gain visibility and enrichment to their collections under the same integrated digital space
- DH Teams: Other collaborative Digital Humanities teams may adopt similar solutions for cultural heritage online corpora that rely on open standards and open architectures
Source Code
Acknowledgements
This project has received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (CROSSREADS, grant agreement no. 885040). A previous instance of I.Sicily on which the requirements of the current solution is based was created and developed by Jonathan Prag, with the technical support of James Cummings and James Chartrand of OpenSky Solutions (see Prag, 2021 and Prag and Chartrand, 2019).